

تواجه نماذج التفكير مثل OpenAI o1 و DeepSeek-R1 مشكلةً تتمثل في التفكير الزائد. فإذا طرحت عليها سؤالًا بسيطًا مثل “ما هو ناتج 1+1؟”، فسوف تفكر لعدة ثوانٍ قبل الإجابة

من الناحية المثالية، ينبغي أن تكون نماذج الذكاء الاصطناعي، مثل البشر، قادرة على تحديد متى تقدم إجابة مباشرة ومتى تخصص وقتًا وموارد إضافية للتفكير قبل الاستجابة. وتقوم تقنية جديدة قدمها باحثون في Meta AI وجامعة إلينوي بشيكاغو بتدريب النماذج على تخصيص ميزانيات الاستدلال بناءً على صعوبة الاستعلام. ويؤدي ذلك إلى استجابات أسرع وتكاليف أقل وتخصيص أفضل لموارد الحوسبة.
الاستدلال المُكلف
يمكن لنماذج اللغة الكبيرة (LLMs) تحسين أدائها في مهام الاستدلال عند إنتاج سلاسل تفكير أطول، ما يُعرف غالبًا باسم “سلسلة الأفكار” (CoT). وقد أدى نجاح تقنية سلسلة الأفكار إلى ظهور مجموعة كاملة من تقنيات توسيع نطاق وقت الاستدلال التي تدفع النموذج إلى “التفكير” بشكل أعمق في المشكلة، وإنتاج ومراجعة إجابات متعددة واختيار الأفضل من بينها.
تُعد “التصويت بالأغلبية” (MV) إحدى الطرق الرئيسية المستخدمة في نماذج التفكير، حيث يتم توليد إجابات متعددة واختيار الإجابة الأكثر تكرارًا. وتكمن مشكلة هذا النهج في أن النموذج يتبنى سلوكًا موحدًا، حيث يعامل كل مُدخل على أنه مشكلة تفكير صعبة ويستهلك موارد غير ضرورية لتوليد إجابات متعددة.
الاستدلال الذكي
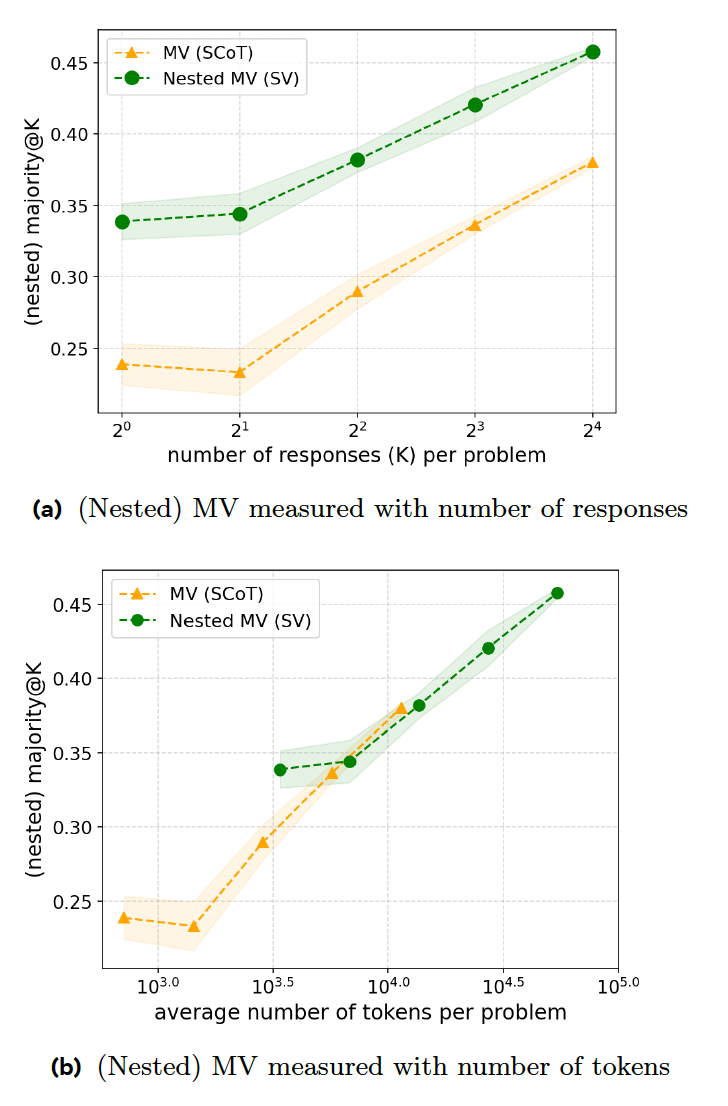
تقترح الورقة البحثية الجديدة سلسلة من تقنيات التدريب التي تجعل نماذج التفكير أكثر كفاءة في الاستجابة. تتمثل الخطوة الأولى في “التصويت المتسلسل” (SV)، حيث يقوم النموذج بإحباط عملية التفكير بمجرد ظهور إجابة معينة لعدد معين من المرات. على سبيل المثال، يُطلب من النموذج إنشاء ثماني إجابات كحد أقصى واختيار الإجابة التي تظهر ثلاث مرات على الأقل. إذا تم إعطاء النموذج الاستعلام البسيط المذكور أعلاه، فمن المحتمل أن تكون الإجابات الثلاث الأولى متشابهة، مما يؤدي إلى التوقف المبكر، مما يوفر الوقت وموارد الحوسبة.
تُظهر تجاربهم أن SV يتفوق على MV الكلاسيكي في مسائل مسابقة الرياضيات عندما يُنشئ نفس العدد من الإجابات. ومع ذلك، يتطلب SV تعليمات إضافية وإنشاء رموز، مما يجعله على قدم المساواة مع MV من حيث نسبة الرمز إلى الدقة.
تقوم التقنية الثانية، “التصويت المتسلسل التكيفي” (ASV)، بتحسين SV من خلال مطالبة النموذج بفحص المشكلة وإنشاء إجابات متعددة فقط عندما تكون المشكلة صعبة. بالنسبة للمشكلات البسيطة (مثل مطالبة 1 + 1)، يقوم النموذج ببساطة بإنشاء إجابة واحدة دون المرور بعملية التصويت. وهذا يجعل النموذج أكثر كفاءة في التعامل مع كل من المشكلات البسيطة والمعقدة.
التعلم المعزز
بينما تُحسّن كل من تقنيتي “SV” و “ASV” من كفاءة النموذج، إلا أنهما تتطلبان قدرًا كبيرًا من البيانات المُعلّمة يدويًا. ولتخفيف هذه المشكلة، يقترح الباحثون “تحسين السياسة المقيدة بميزانية الاستدلال” (IBPO)، وهي خوارزمية تعلم معزز تُعلّم النموذج كيفية ضبط طول مسارات التفكير بناءً على صعوبة الاستعلام.
تم تصميم IBPO للسماح لنماذج اللغات الكبيرة (LLMs) بتحسين استجاباتها مع البقاء ضمن قيود ميزانية الاستدلال. تُمكّن خوارزمية التعلم المعزز النموذج من تجاوز المكاسب التي تم الحصول عليها من خلال التدريب على البيانات المُعلّمة يدويًا عن طريق إنشاء مسارات ASV باستمرار، وتقييم الاستجابات، واختيار النتائج التي تُقدّم الإجابة الصحيحة وميزانية الاستدلال المثلى.
تُظهر تجاربهم أن IBPO تُحسّن من جبهة باريتو، مما يعني أنه بالنسبة لميزانية استدلال ثابتة، فإن النموذج المُدرّب على IBPO يتفوق في الأداء على الخطوط الأساسية الأخرى.
تأتي هذه النتائج في ظل تحذيرات الباحثين من أن نماذج الذكاء الاصطناعي الحالية تواجه صعوبات. حيث تُكافح الشركات للعثور على بيانات تدريب عالية الجودة وتستكشف طرقًا بديلة لتحسين نماذجها.
أحد الحلول الواعدة هو التعلم المعزز، حيث يتم إعطاء النموذج هدفًا ويُسمح له بالعثور على حلوله الخاصة بدلاً من الضبط الدقيق الخاضع للإشراف (SFT)، حيث يتم تدريب النموذج على أمثلة مُعلّمة يدويًا.
والمثير للدهشة أن النموذج غالبًا ما يجد حلولًا لم يفكر فيها البشر. هذه صيغة يبدو أنها قد نجحت مع DeepSeek-R1، الذي تحدى هيمنة مختبرات الذكاء الاصطناعي الأمريكية.
ويشير الباحثون إلى أن “الطرق القائمة على المطالبات و SFT تُكافح من أجل التحسين المطلق والكفاءة، مما يدعم التخمين بأن SFT وحدها لا تُمكّن من قدرات التصحيح الذاتي. ويدعم هذا الملاحظة أيضًا عمل متزامن، مما يشير إلى أن سلوك التصحيح الذاتي هذا يظهر تلقائيًا أثناء RL بدلاً من إنشائه يدويًا عن طريق المطالبات أو SFT.”