

أسماء نماذج الذكاء الاصطناعي مُعقدة للغاية: إليك كيفية تبسيطها
نشهد طفرة في نماذج الذكاء الاصطناعي (AI models). ومع ذلك، تبرز مشكلة متنامية: أصبحت أسماء هذه النماذج مُعقدة بشكل متزايد، تشكل متاهة من الاختصارات والمصطلحات التقنية التي تجعل حتى مُستخدمي الذكاء الاصطناعي المتحمسين في حيرة من أمرهم. يُعقّد هذا الأمر عملية البحث والمقارنة بين النماذج المختلفة، مما يُؤثر على فهم تطبيقاتها وقدراتها.

نحتاج إلى تسميات أبسط لنماذج الذكاء الاصطناعي
على الرغم من مدى ابتكار كل نموذج جديد للذكاء الاصطناعي، إلا أن أسماءها المعقدة تشكل عائقًا كبيرًا للمستخدمين الذين يحاولون فهم هذه النماذج والتمييز بينها. هذه التعقيدات لا تعيق فقط وصول المستخدم العادي إلى هذه الأدوات القوية، بل تخلق أيضًا حاجزًا كبيرًا أمام فهم واستخدام إمكاناتها الكاملة. نماذج الذكاء الاصطناعي، تعلم الآلة، معالجة اللغة الطبيعية، هي بعض المصطلحات المهمة في هذا السياق.
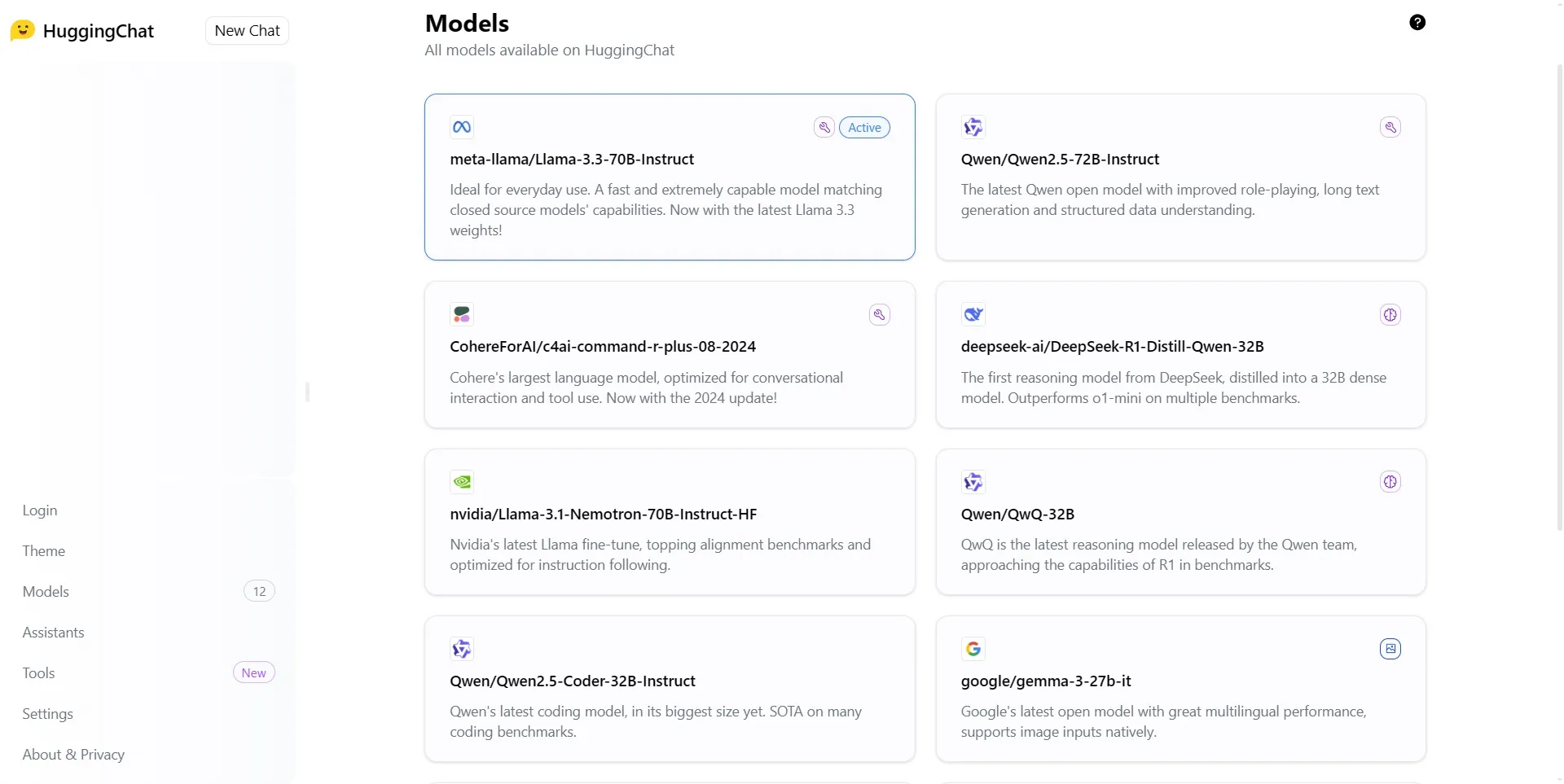
على سبيل المثال، عندما أطلقت شركة التكنولوجيا الصينية العملاقة Alibaba نموذجها Qwen2.5-Coder-32B، من فهم حقًا ما يمكنها فعله؟ كان عليك البحث في المصطلحات المتخصصة لمعرفة ذلك.
بينما غالبًا ما تختار شركات الذكاء الاصطناعي اسمًا إبداعيًا للمنتج، مثل Gemini أو Mistral أو Llama، فإن الاسم النهائي للنموذج يتضمن سمات تقنية معينة، مثل رقم الإصدار أو التكرار، والهندسة أو النوع، وعدد المعلمات، وخصائص أخرى محددة. على سبيل المثال، يشير اسم Llama 2 70B-chat إلى أن هذا النموذج من Meta (Llama) هو نموذج لغة كبير مع 70 مليار معلمة (70B) ومصمم خصيصًا لأغراض المحادثة (-chat).
في جوهره، يعمل اسم نموذج الذكاء الاصطناعي كاختصار لسماته الرئيسية، مما يسمح للباحثين والمستخدمين التقنيين بفهم طبيعته والغرض منه بسرعة – ولكنه في الغالب غير مفهوم للشخص العادي.
تخيل سيناريو حيث يريد المستخدم الاختيار بين أحدث النماذج لمهمة محددة. يواجهون خيارات مثل “Gemini 2.0 Flash Thinking Experimental” و”DeepSeek R1 Distill Qwen 14B” و”Phi-3 Medium 14B” و”GPT-4o”. بدون التعمق في المواصفات الفنية، يصبح التمييز بين هذه النماذج مهمة شاقة.
إن سلسلة أسماء النماذج، كل منها أكثر غموضًا من سابقتها، تؤكد الحاجة إلى تحول جوهري في كيفية تسمية نماذج الذكاء الاصطناعي وعرضها. من الناحية المثالية، يجب أن يكون اسم نموذج الذكاء الاصطناعي تمثيلًا بسيطًا وواضحًا ولا يُنسى للغرض منه وقدراته.
تخيل لو تم تسمية السيارات وفقًا لمواصفات محركها وأنواع نظام التعليق بدلاً من الأسماء البسيطة الموحية مثل “Mustang” أو “Civic”. غالبًا ما تعطي اصطلاحات التسمية الحالية لنماذج الذكاء الاصطناعي الأولوية للمواصفات الفنية على سهولة الاستخدام. وبينما تعتبر بعض المصطلحات ضرورية للباحثين، إلا أنها لا معنى لها إلى حد كبير بالنسبة للمستخدم العادي.
تحتاج الصناعة إلى تبني نهج أكثر تركيزًا على المستخدم في التسمية. يمكن للأسماء المبسطة والبديهية والوصفية أن تعزز تجربة المستخدم بشكل كبير.
طريقة أسهل لاكتشاف الإمكانيات
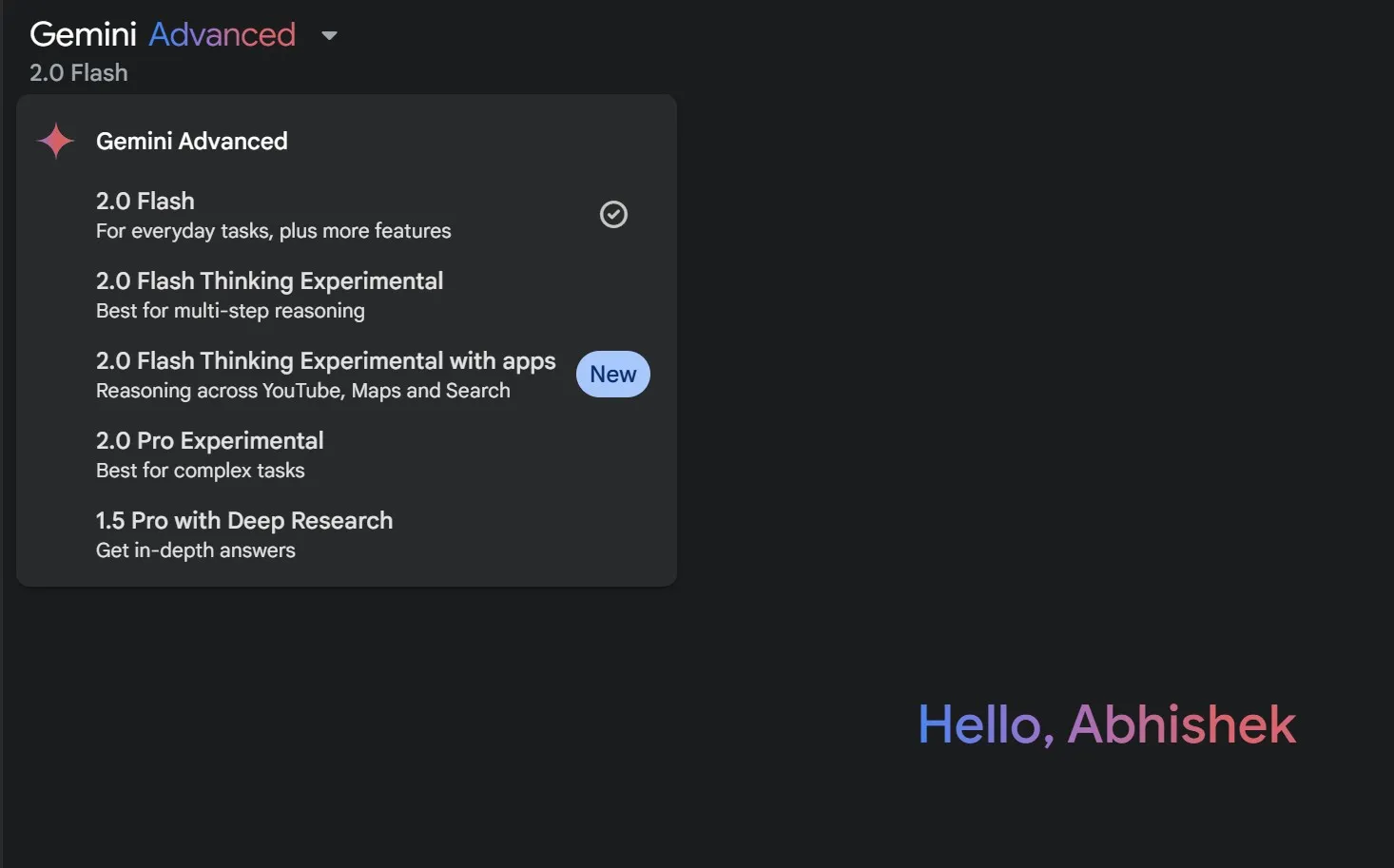
إلى جانب الأسماء المُربكة، يُمثل اكتشاف ما يمكن أن يقوم به نموذج ذكاء اصطناعي مُحدد عقبة رئيسية أخرى. غالبًا ما تكون الإمكانيات مدفونة في أعماق التوثيق التقني. ويتفاقم هذا الأمر بسبب التنوع الهائل للنماذج والوظائف المُتخصصة. قد لا يُعبّر الاسم البسيط وحده عن النطاق الكامل لقدرات نموذج الذكاء الاصطناعي. يعتبر فهم قدرات نماذج الذكاء الاصطناعي أمرًا بالغ الأهمية للاستخدام الأمثل لهذه التقنيات المتطورة.
لحسن الحظ، تُضيف أدوات الذكاء الاصطناعي التي تستخدم هذه النماذج وصفًا موجزًا لتحديد حالة الاستخدام أو إمكانياتها – على سبيل المثال، تُحدد Google أن نموذج Gemini 2.0 Flash Thinking يستخدم التفكير المُتقدم، بينما يُعدّ 2.0 Pro هو الأفضل للمهام المُعقدة. ليس هذا هو الحل الأمثل، ولكن هناك بعض المساعدة. يوفر هذا التوضيح بعض التوجيه للمستخدمين، ولكنه لا يزال محدودًا.
بدلاً من الاعتماد على المصطلحات التقنية، يجب أن تعكس أسماء النماذج وظيفتها الأساسية أو إمكانياتها. إذا كانت الاختصارات ضرورية، فيجب اختيارها بعناية لضمان سهولة تذكرها ونطقها. بالإضافة إلى ذلك، يجب استخدام أرقام إصدارات واضحة وموجزة للإشارة إلى التحديثات والتحسينات. من شأن اصطلاحات التسمية القياسية أن تُبسّط عملية اختيار النموذج.
علاوة على ذلك، يُمكن تصنيف نماذج الذكاء الاصطناعي بأسماء تُعبّر عن وظيفتها الأساسية أو ميزتها الفريدة، مثل “روبوت المحادثة” أو “ملخّص النصوص” أو “معرّف الصور”. مثل هذه الوضوح من شأنه أن يُزيل الغموض عن تقنية الذكاء الاصطناعي. سيُبسّط هذا النهج عملية الاكتشاف، مما يُمكّنك من تحديد نماذج وأدوات الذكاء الاصطناعي الأنسب لمهامك بسرعة دون الحاجة إلى البحث في متاهة من الأسماء والأوصاف الغامضة. سيؤدي ذلك إلى تحسين تجربة المستخدم بشكل كبير.
مع ذلك، تتمتع معظم نماذج اللغات بإمكانيات مُتنوعة ويمكنها القيام بأكثر من مهمة واحدة. لذلك، قد لا يكون هذا النهج مثاليًا لنماذج اللغات الكبيرة المُتقدمة. نماذج اللغات الكبيرة، على وجه الخصوص، تتجاوز التصنيفات البسيطة.

يمكنك بناء سير عمل إنتاجي بسرعة باستخدام أدوات الذكاء الاصطناعي المختلفة.
يمكن أن تكون الحالة الراهنة لأسماء نماذج الذكاء الاصطناعي مُحيّرة. إن التحول نحو تسمية أبسط وطرق اكتشاف مُحسّنة يُمكن أن يُعزز بشكل كبير من تجربة المستخدم ويجعل التكنولوجيا المتطورة في متناول الجميع. إلى أن يحدث ذلك، يُمكن أن يساعد البقاء على اطلاع دائم والاستفادة من موارد المجتمع وتجربة نماذج مُختلفة المستخدمين على التنقل في عالم الذكاء الاصطناعي المُعقد. من خلال البحث والتجريب، يمكن للمستخدمين تسخير قوة الذكاء الاصطناعي بشكل فعال.